當前,海量的AI應用、遊戲、雲服務等領域急需一款高性能GPU來滿足廣泛的市場需求。近期,中(zhōng)國一站(zhàn)式IP和(hé)芯片定制賦能企業(yè)芯動(dòng)科技于2021年11月(yuè)率先發布了高性能服務器(qì)級GPU-風華1号。
這款高性能GPU演示的實際參數和(hé)性能令人頗感興奮,其中(zhōng)B卡涉及的Chiplet技術(shù)更是吸引了市場眼球。


風華1号GPU發布
公開的數據顯示,B型卡通(tōng)過Innolink Chiplet技術(shù),将兩顆GPU聯級,實現性能翻倍。
發布會上,芯動(dòng)透露Innolink是自主研發的Chiplet标準通(tōng)信協議,在摩爾定律趨近失效、先進工藝成本高昂的市場狀況下(xià),開拓出的新技術(shù)路(lù)線,為高性能計算、5G、元宇宙、雲遊戲、雲服務等應用提供異構集成的基礎連接技術(shù)。
本文(wén)中(zhōng),我們将揭開Innolink Chiplet黑科技的神秘面紗,詳細探讨Chiplet技術(shù)能帶給我們的驚喜。
1、Chiplet的發展趨勢
需求,永遠(yuǎn)是最好的技術(shù)發展推動(dòng)力!
簡單來講,Chiplet就是将芯片的各個(gè)功能模塊像樂(yuè)高積木一樣拆分開來,再根據需要組織拼接在一起,具有靈活、成本低的特點。
早在2000年IBM就提出了集成電路(lù)Chiplet技術(shù)的概念,但是Chiplet作為新的異質集成(heterogeneous integration )技術(shù)的一部分,在當時并沒有掀起太大的波瀾。畢竟在那個(gè)年代,摩爾定律穩定延續,各晶圓廠在制程發展上一日千裡,将SoC的各個(gè)功能模塊放在同一晶片(monolithic)上是劃算且高效的。

IBM System z10 Multi-Chip Module
直到2014年左右,最先進的晶圓制造工藝到達16/14nm時,急劇上升的制造成本和(hé)設計難度,讓Chiplet技術(shù)看起來越發誘人。一個(gè)新的28nm節點的SoC開發成本達到了5千萬美元左右,小功能的疊代也達到了2千萬美元左右,5/7nm的SoC成本更是達到了3-4億美元。這樣高昂的成本,别說初創公司,對于芯片巨頭來說也是難以承受的,于是探索Chiplet技術(shù)來延續摩爾定律成為了業(yè)界共識。
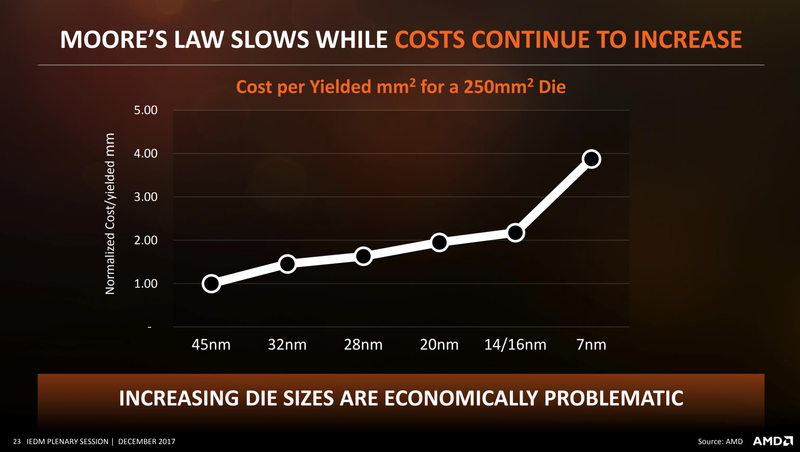
引用AMD的數據,随着工藝的發展,成本劇增
2014年,海思與台積電合作推出了自己第一款Chiplet産品,使用的台積電CoWoS技術(shù)。
2015年,Marvell推出了Chiplet架構智能手機處理器(qì)Mochi。
2017年,AMD推出EPYC系列采用Chiplet技術(shù)實現對Intel的彎道超車(chē)。

AMD EPYC處理器(qì)成功實現了集成最高達64x核的高性能服務器(qì)芯片
AMD在EPYC和(hé)Ryzen系列處理器(qì)上取得了巨大的成功,将Chiplet技術(shù)推向了行業(yè)的風口,一時間各個(gè)芯片巨頭紛紛大力投入Chiplet相關(guān)技術(shù)的實現。
英特爾為了應對AMD的挑戰,于2018年将 EMIB(嵌入式多矽片)技術(shù)升級為邏輯晶圓3D 堆疊技術(shù)Foveros。英特爾的EMIB(Embedded Die interconnect bridge)技術(shù)提供了Chiplet所需要的高性能連接帶寬。

3D-Foveros結構圖
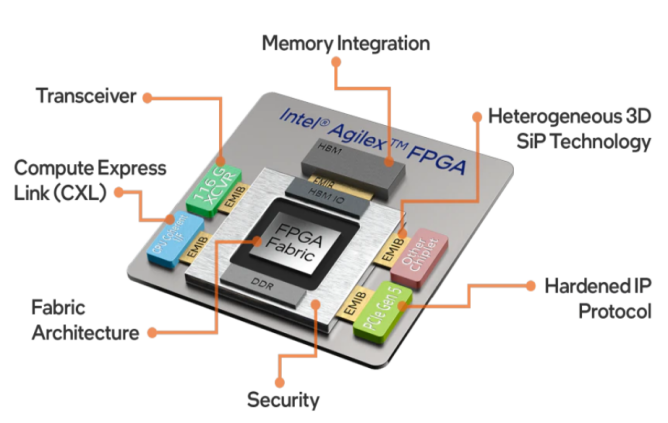
Intel Agilex-EMIB結構圖
Intel Lakefield系列Hybrid技術(shù)采用了3D-Foveros的封裝結構,以及FPGA系列主流産品Stratix和(hé)Agilex。與AMD水平布局Chiplet不同,Intel采用了垂直和(hé)水平相結合的Chiplet連接結構-3D Foveros。Intel作為IDM擁有自己的晶圓廠,在Chiplet封裝的多樣性和(hé)疊代上更有優勢。借助這些優勢,Intel 推出了EMIB、HBM 的3D 封裝、AIB 的總線、Foveros、CXL 等一系列異構集成技術(shù)。
2、Chiplet的HBM形式
HBM(High bandwidth memory)也是Chiplet異構集成技術(shù)的一種,用于存儲芯片堆疊互聯的技術(shù),将存儲晶片和(hé)處理器(qì)Die一起連接封裝在一起,實現高速的内存數據交換。
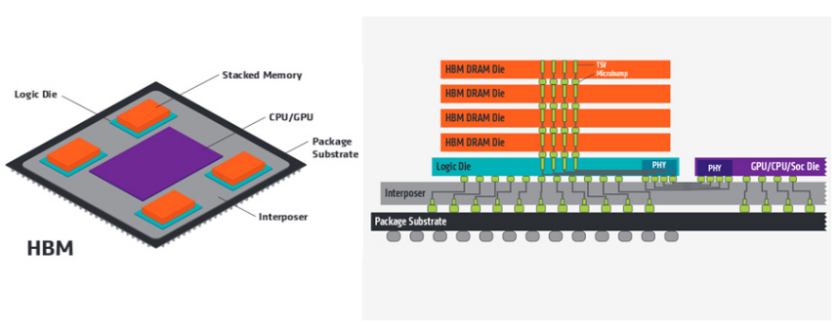
HBM的DRAM Die疊加
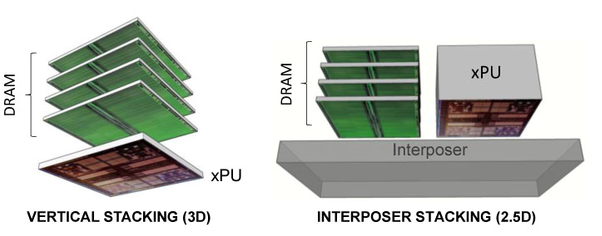
3D/2.5D的模型
DRAM Die像疊積木一樣壘起來,兩種形式稱為3D/2.5D封裝技術(shù)。
2015年AMD發布首款采用HBM堆棧顯存的最新旗艦顯卡Fury -X,堆疊8GB顯存。

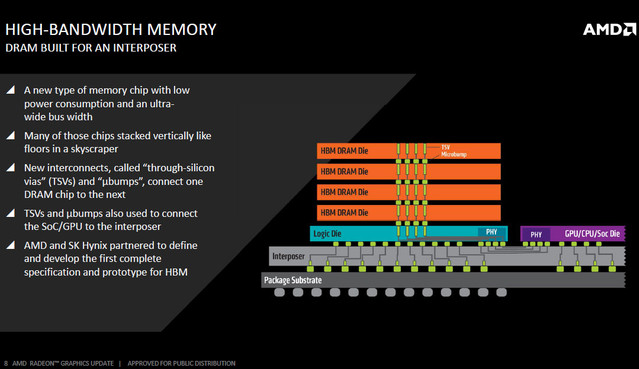
GPU/CPU通(tōng)過interposer連接異構存儲單元,降低了系統的latency延時,減少(shǎo)PCB的空間和(hé)成本,提高運行性能。

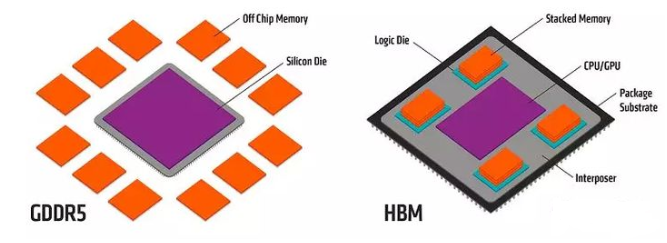
顯卡的小巧和(hé)緊湊得益于HBM的顯存堆疊技術(shù)縮減芯片面積
HBM常用于高密度的内存單元堆疊,比如(rú)DRAM和(hé)Nand存儲的結構,這兩種垂直設計,矽片雖然堆疊在一起,但是并不會直接相連,而是通(tōng)過wirebond或者通(tōng)孔(Silicon Vias-TSVs)連接到底層基闆上。

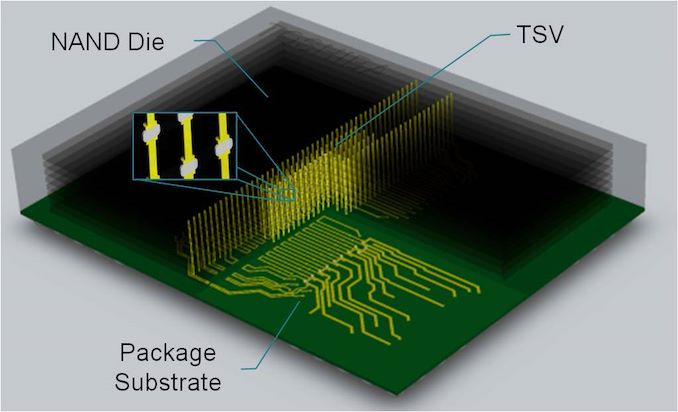
三星的Nand Die堆疊連接
全球主流内存廠家都在采用堆疊技術(shù)增加存儲的密度,包含三星、美光、海力士等等都有各自的HBM實現産品。
近年來高性能計算、人工智能、自動(dòng)駕駛,、雲遊戲等應用,推動(dòng)了高并發、高帶寬的計算需求。HBM正是在這樣的需求推動(dòng)下(xià)飛速發展,HBM2定義可(kě)以實現每個(gè)封裝高達256GB/s的内存帶寬(DRAM堆棧),JEDEC提出最新的HBM2E規範,最高可(kě)以實現每堆棧461GB/s的帶寬。
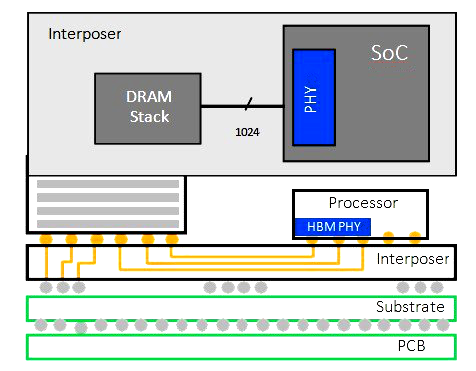
HBM與處理器(qì)混合異構集成封裝是很多高性能計算産品的主流設計
3、Chiplets的優勢和(hé)面臨的挑戰
前面介紹了Chiplet在市場上的應用和(hé)發展趨勢,接下(xià)來,我們就Chiplet技術(shù)的主要優點和(hé)面臨的挑戰來展開論述。
3.1有效提高良品率,降低成本
我們通(tōng)過計算來直觀展現,Chiplet是如(rú)何提高良品率的。舉個(gè)例子(zǐ),12寸晶圓直徑為300mm,假設壞品率為0.1/cm²,按以下(xià)2種方案劃分:
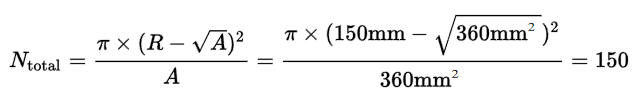
按整顆360mm²/die可(kě)以切割出150顆

劃分成4xchiplet(99mm²/die)可(kě)以切割出622顆
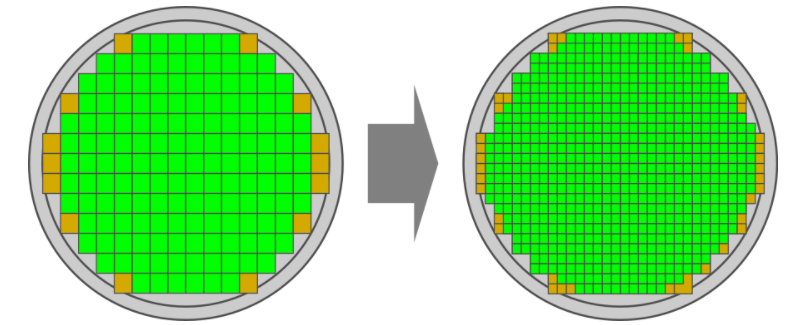
4xChiplet示意圖
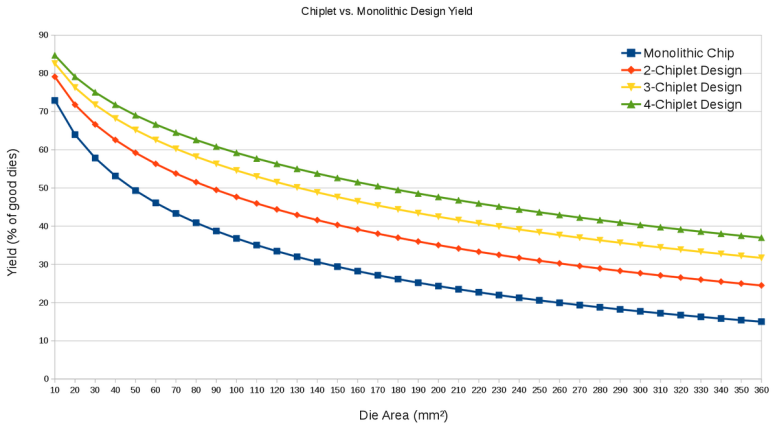
Chiplet數量在晶圓制程的良品率變化
12英寸的晶圓,将原360mm²/die劃分變成4xChiplet(99mm²/die)之後,良品率從15%提升到了37%,實現翻倍。雖然4-Chiplets的設計會增加10%左右的損耗,但是良品率的大大提升,仍然有效地降低了整體成本。
原理很簡單,晶圓的壞點分布比例是一樣的,當die的面積越小,數量越多,分母就越大,壞品率就越低。
3.2 IP模塊chiplet劃分,靈活複用,降低開發周期和(hé)成本
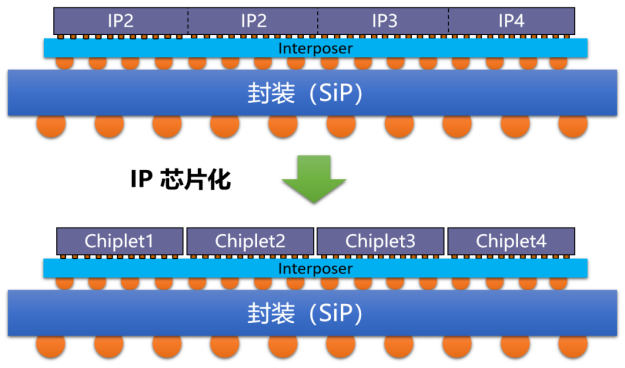

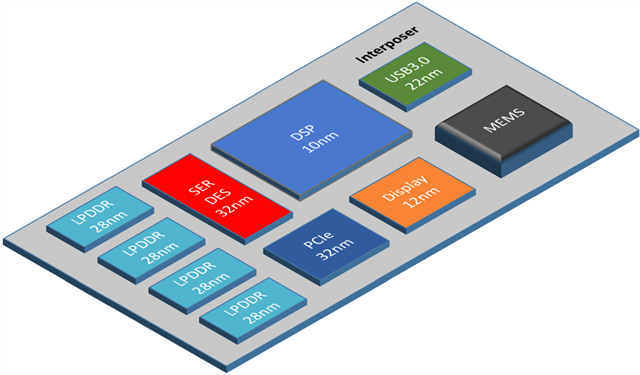
Heterogenous integration -将功能模塊分離(lí)到性價比最合适的Chiplet上
模塊化的開發思路(lù),将單晶片(Monolithic)的IP功能模塊分離(lí)(Disaggregate )到Chiplet上,注意上圖中(zhōng)CPU核的Chiplet是7nm,而IO是14nm制程工藝,如(rú)果有存儲模塊可(kě)能是17nm或者更低的工藝。
在一顆複雜的SoC裡,并不是所有的模塊都适用于先進工藝的設計。一般來講晶體管密度較高的CPU/GPU計算單元選用先進的5/7/12nm的生産工藝,但先進工藝的晶片對模拟電路(lù)IO功能卻并不友好(電壓幅值太低),低速的通(tōng)信接口比如(rú)I2C、UART、USB2.0等用28/40nm的便宜工藝都夠用了,殺雞不用宰牛刀。
Chiplet将功能模塊分離(lí)開了,像樂(yuè)高積木一樣,重構一個(gè)SoC不再需要重頭開始設計,一些現成的Chiplet模塊可(kě)以實現即插即用的效果,有效地降低了開發的周期和(hé)成本。

而且異構集成Chiplet,可(kě)以将缺陷的Chiplet/Die/芯粒靈活剔除掉,以往的單晶片Monolithic隻要有一個(gè)小部分壞了,那整顆晶片Die就算是廢品了,而Chiplet的結構可(kě)以将缺陷部分篩除掉,避免了這樣牽一發而動(dòng)全身的風險。
總而言之,将SoC分解Chiplet實現,高性能運算部分使用先進工藝,模拟的、低速的模塊劃分到低工藝的晶片上實現,既節省了成本、降低了開發周期,又匹配了各自的性能發揮。
3.3 Chiplet技術(shù)發展面臨的挑戰
毫無疑問(wèn),Chiplet技術(shù)有着巨大的優勢和(hé)發展潛力,各頭部芯片公司的Chiplet産品發布與疊代也展現了其發展趨勢。當然,我們仍然要看到Chiplet技術(shù)發展面臨的挑戰,總結經驗、評估風險才能把握發力方向,走得更遠(yuǎn)更紮實。
封裝技術(shù)的考驗
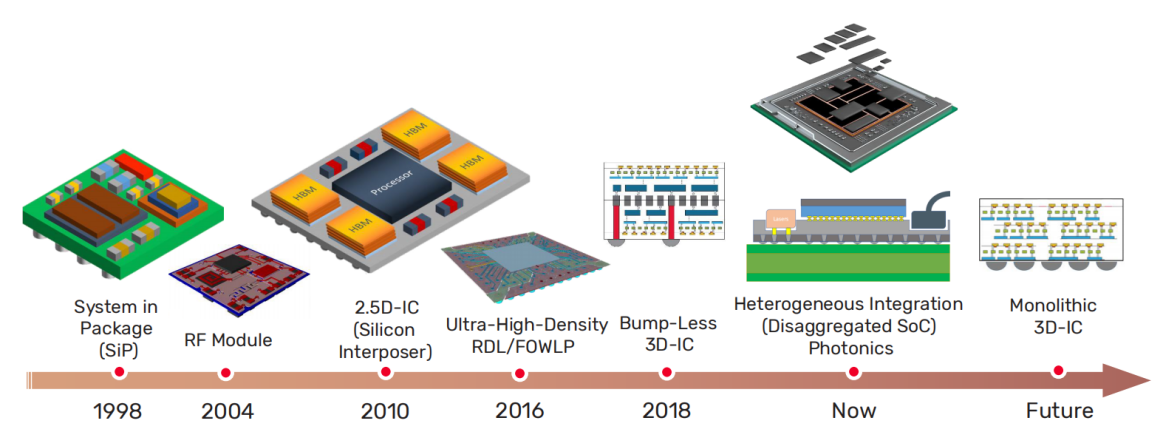
Muti-chip(let)異構封裝的發展
當前Chiplet的需求來源于高性能計算,人工智能的複雜SoC模塊分解,對速度和(hé)信号完整性有着極高的要求,傳統的SiP(System in Packaging, 系統級封裝)仍然需要加強工藝的優化。
半導體頭部的制造商(shāng)如(rú)Intel、TSMC、三星以及封測代工(OSAT)等都推出了各種Chiplet 2.5D/3D封裝方案來滿足市場的需求。
Intel推出EMIB(Embedded Multi-Die Interconnect Bridge,嵌入式多核心互聯橋接)和(hé)3D-Foveros。
TSMC推出了整合芯片系統(SoIC)、InFo(Fanout)和(hé)CoWoS系列。
三星也發布了2.5/3D封裝技術(shù)I-Cube(2.5D)/X-Cube(3D)。X-Cube,通(tōng)過TSV矽穿孔技術(shù)将不同芯片Die包含内存SRAM、邏輯運算等堆疊,節省空間面積。
當前市場主流的高端FPGA、CPU、GPU芯片大量采用了2.5D封裝技術(shù)。
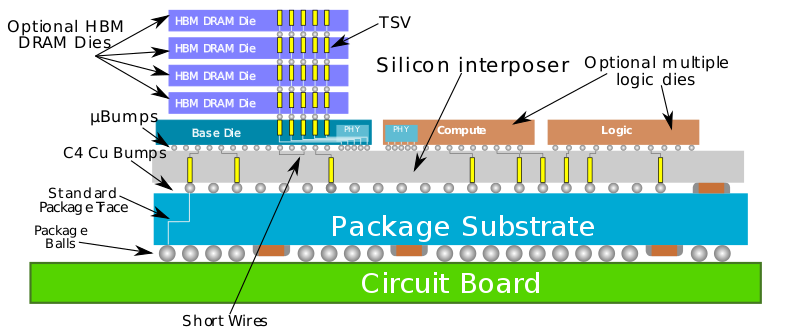
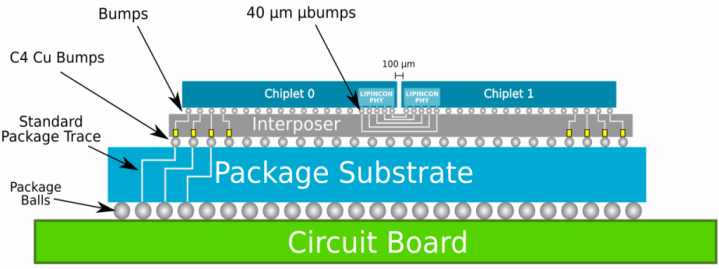
Interposer 實現了内存,Chiplet等各個(gè)模塊的連接
Chiplet的互聯标準
既然單晶片SoC切割成不同的Chiplet芯粒,以便于重用複用,異構集成芯片可(kě)能會包含不同制程甚至不同廠家提供的Chiplet,統一的接口是保證信息交互的重要保證。
Marvell的異構Chiplet芯片Mochi采用了Kandou協議。
NVIDIA有GPU的高速互聯NV Link方案。
Intel 推出了EMIB(Embedded Die interconnect bridge)接口。
TSMC和(hé)Arm合作推出了LIPINCON協議。
AMD采用Infinity Fabrie總線互聯技術(shù)。
各家芯片廠商(shāng)有各自的協議,僅僅在自己内部實現了Chiplet互聯,但是随着市場的發展與需求的推動(dòng),必然會出現不同廠商(shāng)Chiplet互聯的應用。統一的标準接口則是行業(yè)發展的基礎,各種組織和(hé)行業(yè)協會自然而然開始了标準化工作。
DARPA推出“CHIPS(Common Heterogeneous Integration and IP Reuse Strategies)”計劃,該項目希望通(tōng)過模塊化和(hé)可(kě)重用方案降低國防技術(shù)研發的成本,其成員包含了波音、Cadence、Intel、洛克希德·馬丁、美光、Synopsys等行業(yè)領頭羊。
2018年7家公司成立ODSA(Open Domain-Specific Architecture)組織,研究制定Chiplet開放标準、推動(dòng)Chiplet産業(yè)發展。
2019年,Intel聯合阿裡巴巴、思科、戴爾、Facebook、Google、HPE、華為和(hé)微軟成立Compute Express Link(CXL)開放合作聯盟,實現CPU與GPU、FPGA等專用加速器(qì)之間的高速、高效互連。
可(kě)以說,Chiplet技術(shù)對當前突破AI和(hé)CPU/GPU等計算芯片的算力瓶頸具有重要意義。作為國内一站(zhàn)式IP和(hé)芯片定制賦能企業(yè),芯動(dòng)科技已推出了自主研發的INNOLINK Chiplet和(hé)HBM2E等先進IP,支持高性能CPU/GPU/NPU芯片的異構實現。在産業(yè)發展大背景下(xià),芯動(dòng)科技為Chiplet的标準化貢獻和(hé)IP解決方案,顯得尤為重要。
4.Innolink™ Chiplet 一站(zhàn)式解決方案

芯動(dòng)的IP目錄豐富有大量的場景驗證實現
芯動(dòng)科技是成立于2006年的老牌IP技術(shù)廠商(shāng),有着16年的技術(shù)疊代,超過200+次的流片紀錄,60億顆授權量産芯片,超過10億顆的高端定制soc量産。在高性能計算/多媒體&汽車(chē)電子(zǐ)/IoT物聯網等領域,芯動(dòng)解決方案具有國際先進水平,涵蓋DDR5/4、LPDDR5/4、GDDR6X/6、HBM2e/3、Chiplet、56G/32G SerDes(含PCIe5/4/USB3.2/SATA/RapidIO/GMII等)、HDMI2.1、ADC/DAC、智能圖像處理器(qì)GPU和(hé)多媒體處理内核等多種技術(shù)。
這些高速接口主要應用在高性能計算、5G通(tōng)信、自動(dòng)駕駛、人工智能、大數據存儲、雲計算、高性能圖像媒體處理等領域,芯動(dòng)的Chiplet解決方案有着實際的需求支撐和(hé)疊代基礎。
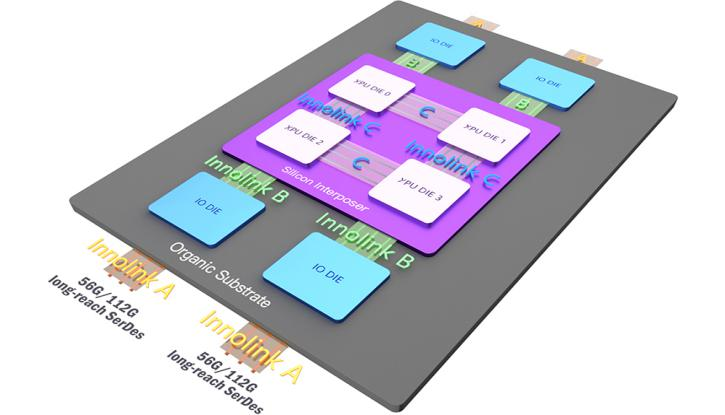
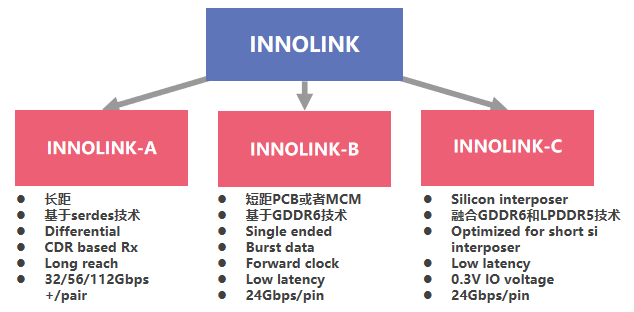
Innolink Chiplet有3種連接方式
Innolink™包含Chiplet Die-to-Die (D2D)、Chip-to-Chip (C2C)、Board-to-Board (B2B) 和(hé) Package-to-Package (P2P)等多種連接需求。
Innolink™ Chiplet具有自主知識産權,滿足了廣大客戶的異構集成技術(shù)需求,成功應用于高性能GPU及其他高性能計算芯片,為高性能芯片的發展提供了一條新的道路(lù)。
結語
Chiplet發展需要整個(gè)半導體産業(yè)鍊的協同分工,從芯片設計、EDA工具、晶圓制造到封裝測試,需要統一的标準和(hé)工藝升級,這需要時間探索和(hé)協作,不斷地疊代前進。
一項技術(shù)發展的最大動(dòng)力還是來源于需求的推動(dòng),在摩爾定律趨于失效的情況下(xià),高性能計算、人工智能、雲服務、雲遊戲等需求仍然在爆炸式的增長,單晶片(Monolithic)SoC已經逐漸不能滿足性能和(hé)成本的要求,市場需求必然會推動(dòng)Chiplet産業(yè)的快速發展。
當前背景下(xià),自主創新的、可(kě)以持續疊代和(hé)發展的Chiplet技術(shù)顯得尤為重要,這能讓企業(yè)保持在高性能芯片領域的先進性。芯動(dòng)科技的Innolink™ Chiplet技術(shù),已被成功運用于其自研的高性能GPU“風華1号”中(zhōng),大大提升了性能和(hé)帶寬,成為該領域的異構集成設計的實踐者。我們也期待芯動(dòng)在Chiplet、GDDR6/6X、HBM2E、SerDes等先進IP的進一步積累和(hé)發展,持續賦能Chiplet産業(yè),幫助高端芯片縮短(duǎn)設計周期、降低設計成本,加快産業(yè)鍊芯片升級!

 官方公衆号
官方公衆号 招聘公衆号
招聘公衆号
